
Entropy?
In information theory, entropy is the opposite of predictability or certainty. For example, before a die roll (6 options) there is more uncertainty about the outcome than before a coin flip (2 options). This post deals with character entropy: how predictable are characters within a text? One kind of character entropy appears to set aside Voynichese the most from “normal” texts: h2, conditional entropy. What this means is best explained through some examples.
Take the letter “q” in English as our current character. When q is the first letter of an English word, which letter will follow? This is easy to predict: u. So the entropy here is low; In fact, when q is not followed by u in English, the word is likely foreign, like in Qom (the seventh largest city in Iran), Qatar, qanat, Qin etc. The tendency of q to be followed by u decreases the character h2 of English.
On the other hand, the letter r can be followed by almost anything, in alphabetical order: rat, curb, starch, lard, red, wharf, surge, Rhode, rise… you get the picture. This increases conditional entropy because it’s hard to tell what will follow r. Note that even when a letter can be immediately followed by many others, it might still prefer one or two. This again influences entropy statistics.
Character h2 of Voynichese is notoriously low, which means the next character is often predictable. In general, [i] is followed by [i] or [n]. And [n] is mostly followed by a space. [q] is followed by [o] and so on.
EVA?
What I’d like to do today is run some tests to see how the commonly used transcription alphabet EVA influences Voynichese h2 values. The thing to understand about EVA is that it is, in part, stroke-based. Consider the following word, how many letters would you count?
Minimally, one would count four, all separated by a tiny space: a big loopy thing, a horizontal bar with two legs, something that looks like “u”, and something like 9. But you could also count more: the first one could be a ligature, the second one as well, the “u” could be two c’s. So one could reasonably transcribe the above using four to seven characters. In EVA, this would be [kcheey]. We transcribe some groups of strokes as one glyph (k), but others are pulled apart (ee).
I think EVA is well-designed and serves its purpose. We simply don’t know the Voynich glyph inventory, so a balance has to be found between transcribing as single glyphs or strokes. But I often wonder what the effect would be if these are divided differently. This post is not meant as a proposed “correct” way of transcribing Voynichese. I’m just exploring the impact of some options.
(Check the Wiki page on minims for examples of how dividing strokes into glyphs was also problematic in Gothic scripts.)

Voynich Entropy
The conditional character entropy of Voynichese-as-EVA is unusually low, so it is often easy to predict what the next glyph will be. How low exactly?
The first experiment I did to get a feel for these values involves four texts:
- the first 40,000 characters of VM Quire 13 (including spaces)
- the first 40,000 characters of Pliny’s natural history (including spaces, all lowercase, punctuation removed).
- the exact same Q13 text but with all characters scrambled randomly
- the exact same Pliny text but with all characters scrambled randomly
The Q13 scramble starts like this. Note that there are also consecutive spaces but WordPress removes those.
a herko akndcclyq lohlkeseal ld y k qhsy qyhedo dyekooylosspi eea okolyleh actqaeqyk dqoqetyholeotyoordhdnkdhdnl ded e yyo h yd hed h eqecal paqkdet le y te cyqiscyedfyryoleeh qeqayaeeekqyy ooieyooldkq yl skos r drks kn nd y dy e n qhooqynkonlkhcsylyee ptn yoa q lleqydk oootnshl a yec ddkhdnnooi yede dlcded y q tqyyo dket a yehdeckio o ho ee hhaih r lyhrks ciceqosedcehk klyqadehrhyhhtatal soi qoylao eyak hk cikhs oqpenyaed e dcyehy aqceeeocioyyyhaqdnyo ielleeghey lelrl loshro kykay r laod scilie
And here’s an example from the Pliny scramble:
buondseiaelsmtbr me remlatpaciut toofuantu iisnaiai enilin e uriuvprh ttciougiielosgr ci o suoob tlauee csvuescscctus aap s npiaeeu uiniieaoasnpua cif muma r irimiaeirmmtxs enctpeurtaieaecseadbdf npaet rsuuroe amei le bux di s iasneniue boseirnur anus tnalmmmri tssdneu enrnmtemqnocisneciseepeu un l dtn irfeheirsburrtdui rquim setem l mfninesqbe c nnviiuqmeedoedmi traaolrnt asrsvqnuc uno uitesor
(It’s funny to see how even after scrambling, you can still spot which one is EVA).
What’s the point of this? Well, scrambling adds entropy; it breaks down any patterns present in the text, and predicting the next glyph is now purely a matter of knowing glyph frequencies and always guessing the most common one. Think of it as shuffling a sorted deck of cards: your chances of correctly predicting the next card will plummet after shuffling.
Here’s how the conditional character entropy of these four texts compares, expressed as a fraction of their theoretical maximum entropy.
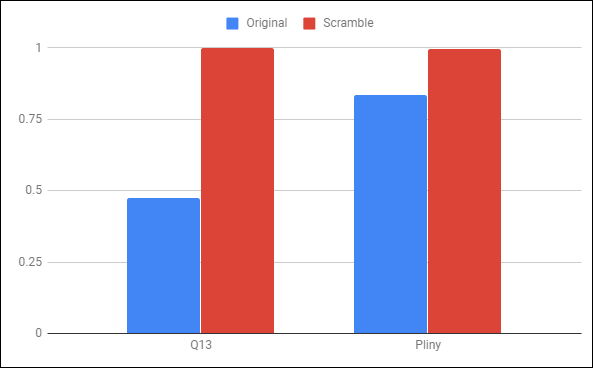
For the original texts (blue columns), Voynichese is much more predictable than Latin, resulting in a low h2. But both scrambled texts (red) achieve high h2 values close to the maximal entropy for their respective texts.
But what about other scripts, abjads…? Latin script might be our best bet. I tested Greek and its h2 is much higher, while we need lower. Lindemann [1] explored Arabic, Syriac and Amharic, again leading to a higher h2. He also tested texts transcribed with abbreviations maintained, which again did not lower h2.
Let’s make some entropy!
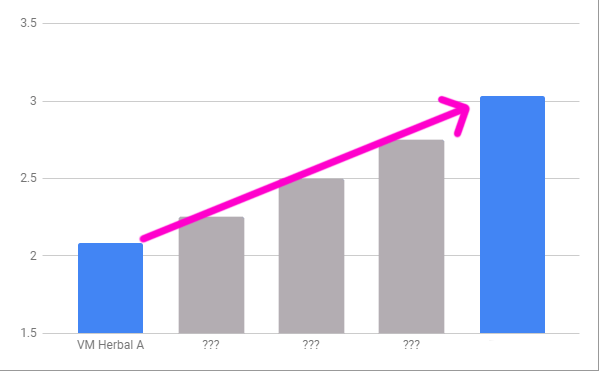
The low end for conditional entropy in European texts is around 3.0, while Herbal A does best for Voynichese, with h2 = 2.1. That’s an enormous difference. But our transcription is in EVA, which lowers entropy; Lindemann calculated that Currier’s transcription would increase VM entropy to about 2.4, which is still low. [2] Many of the tweaks I can make on basic EVA will bring it closer to Currier.
So this is our goal. Let’s start from EVA and see which changes we can make, and what their impact is on h2. Again, this is no proposed solution or correction, just an experiment with statistics.
1. EVA [ch] and [sh]
There are a few obvious starting points, and one of them is what we call “bench characters”, transcribed in EVA as [ch] and [sh]. Transcribing them as one character (which they may well be) instead of a bigram should increase entropy a bit. But by how much? Since character entropy is case sensitive, it is convenient for me to use uppercase for any replacements I make. So I’ll use C and S.
[ch] –> C
[sh] –> S
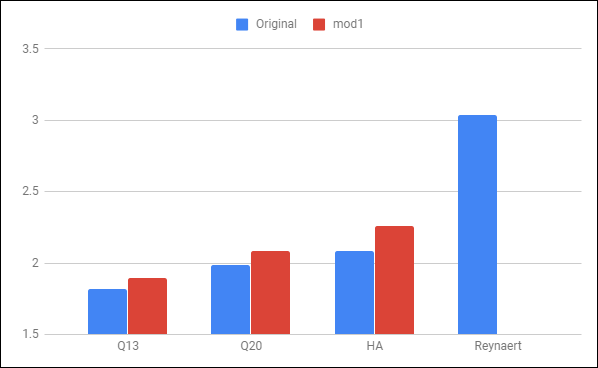
This modification has a noticeable impact on h2, but we still have a long way to go.
Herbal A will give us the best shot, so I will drop Q13 and Q20 from further graphs. I’ll also use (h2/h1) from now on, since I’ve been told (by Anton) that h1 must be taken into account when comparing various texts. This can be done in various ways, but I like h2/h1 because this gives h2 as a percentage of the text’s maximal h2.
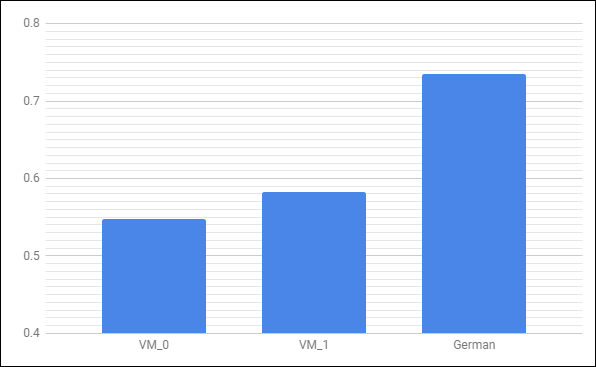
In the above graph, VM_0 is the original 40,000 character text from Herbal A. VM_1 is the first alteration. Subsequent alterations will be cumulative, so ideally they will appear between VM_1 and our goal.
This first transformation brings us from 55% to 58%.
2. EVA [ckh, cth, cfh, cph]

These are what we call benched gallows. They are complex characters, and we don’t quite know how to handle them. Recently, JK Petersen explained on the forum that stacking letters like this was not uncommon in Greek, and that there is no fixed order to read them. This leaves me with three options: transcribe as bench-gallow, gallow-bench or a unique character.
Bench-gallow beats the other options by a tiny margin, so I’m going with that
[ckh] –> Ck
[cth] –> Ct
[cfh] –> Cf
[cph] –> Cp
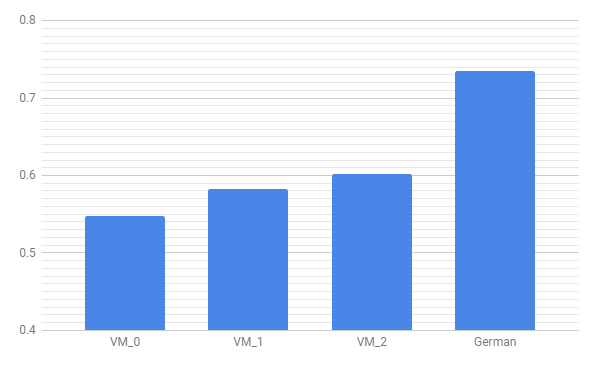
And so we cross the barrier of 60%… barely.
3. [i]-clusters
Ignoring rare cases, [i], which is basically a minim, can only be followed by [n], [r] or another [i]. The number of [i] in such clusters varies.

[iin] –> M
[in] –> N
[iir] –> W
[ir] –> V
My reasoning is that [n] might just be [i] with a decorative swoop (flourish). In that way, it makes sense to count it as a minim as well. Next, I converted the few remaining ii-clusters to their corresponding uppercase letter, again treating them like minims in Gothic script.
[iii] –> M
[ii] –> N
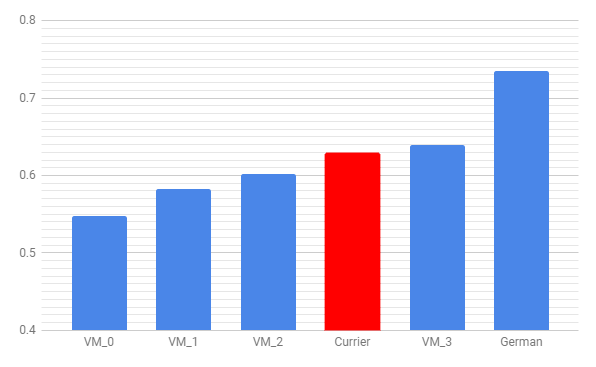
Much to my surprise, this iteration (VM_3) surpassed Currier’s transcription, which I’ve added in red:
4. EVA [q]
Next up is EVA [q]. This is almost always word-initial and followed by [o]. Both characteristics have a negative impact on entropy. Currier transcribed [qo] as [q], which seems like a good idea.
[qo] –> q
Somewhat surprisingly, this hardly raises h2. I suspect that collapsing [o] into [q] is not enough to offset the effects of [q]’s word-initial position. No graph, the difference is only 0.0025.
5. EVA [e]
EVA [e] is like [i] because it often appears in improbable sequences. For example, Herbal A contains the word [deeeese].

As you’ll notice above, the central [eeee] cluster comprises two parts, and indeed [ee] is often connected. I will therefore consider [ee] a single glyph.
[ee] –> U
Again, this change has very little impact. I think two things are happening:
- With the new glyphs I’ve been introducing, h0 goes up. And with that, h1 rises as well: with a larger glyph set, you can create larger entropy. Hence, h2/h1 remains constant, while we need it to go up.
- Despite collapsing frequent glyph pairs, there is still a rigid structure. I’m just kicking the can down the road.
Time to bring out the big guns.
6. EVA [y]
One of the first things I noticed when going over a page of Voynich text years ago is that [y] is [a] with a tail. Additionally, they are in complementary distribution; [y] favors the beginning and ends of words, places where we don’t find [a]. [3]
What would happen if I change [y] to [a]? When transcribing a regular medieval text, we would also ignore place-dependent variations of the same glyph. We don’t know whether that is what’s going on here, but all things considered, the concept is not unusual.
[y] –> [a]
The impact is considerable:
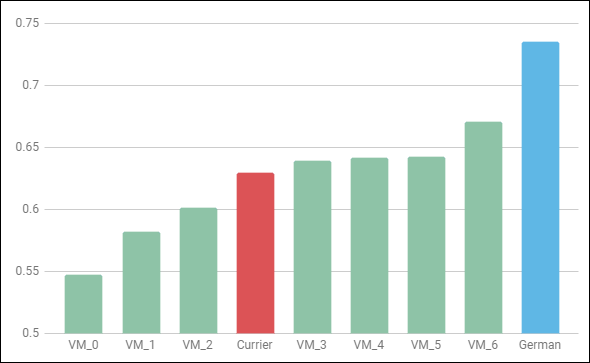
You can see that after VM_3, I had gotten the most out of collapsing possible digraphs into single characters. At VM_6, the pace picks up again because I eliminated [y], which might be a positional variation of [a].
Conclusion
I changed several common bigrams and trigrams into single characters and turned [y] into [a]. These tweaks increased the conditional character entropy of Herbal A from 55% of its maximum to 67%. This is an improvement, but still very low. H2 itself went from 2.09 to 2.43, which is still far from the target of 3.00.
The changes to bigrams that had most effect involved benches and [i]-clusters. For both, arguments can be made that they are better represented as single glyphs for entropy calculations. In the next alterations to bigrams, however, I noticed I had reached the ceiling.
If more progress is to be made, it might be necessary to detect other situations like [a] and [y], where two glyphs might be positional variations of the same “phoneme”. If you have any suggestions, I’ll gladly test them.
NOTES
As usual, I owe thanks to the helpful people at the Voynich.ninja forum. Among others Nablator for the code, Anton for his entropy tutorial and Rene for various pointers on statistics.
[1] This post was in part prompted by the slides for a 2018 talk by Luke Lindemann (pdf) exploring the relation between transcription and character entropy.
[2] Alternatively, one could use Glenn Claston’s transcription, but this has its own problems. Claston attempted to include smaller differences between glyphs which might be meaningful. Still, with all these variables added, h2 for the first 40,000 characters is “only” 2.6. What’s really problematic is that this transcription’s h0-h1 is two to four times as large as that of other texts. Even for a modern Flemish news article including capitalization, numerals and punctuation, h0-h1 is 2.0, compared to 3.1 for Claston.
[3] The complementary distribution of [a] and [y] was pointed out by Emma May Smith, although she does not believe the difference is merely ornamental.

a-y equivalence is a bit of an acquired taste, not sure if you’re going to get many at your restaurant with that on the menu.
Having said that, I’ve spent a long time suggesting that ar/or/al/ol/am (I expect om will turn out to be a copying slip for am) should also be parsed as tokens, and that there’s a good chance dy will too (I’m kind of 50-50 on dy). I also wondered in Curse whether o+gallows and y+gallows should be parsed as (verbose) tokens. Moreover, I think an/ain/aiin/aiiin and air/aiir/aiiir should also be read as tokens, rather than breaking them down into strokes below that.
LikeLike
Thanks, Nick, I will test those in the next post.
When I’d replace all of those I’d add many new characters though. Over 20, if all gallow combinations are different. That would blow h0 through the roof.
If you want to get values like in a normal text, at some point you’ll have to see how you can get one character to appear in various locations of the word. Otherwise you’re stuck with the same low entropy, only with a larger glyph set.
LikeLike
Don’t forget (a) we can’t see any numbers, (b) line-terminal EVA -am may nothing more complex than a hyphen token, and (c) I believe that word-terminal EVA -y may well be a truncation token, while EVA -dy may well be a similar (but perhaps longer) truncation token. So there could well be plenty of non-alphabetic tokens in the Voynichese plaintext, not just letters.
LikeLike
True. But if we have to “spend” tokens on numerals and punctuation, I wonder what’s left for actual text.
Punctuation is especially difficult to test statistically because you can’t compare it to a modern text or a transcription with modern punctuation.
LikeLike
Still, if it’s a technical text of some sort, then we should expect numbers at the very least. And the line-terminal -am hyphen looks quite likely to me too. And I don’t have any kind of explanation for EVA -y other than truncation that makes sense. Oh, and the frequent top line pair of single-leg gallows (“Neal keys”) is probably delimiting some kind of meta-information too.
So we may well have a good number of non-alphabetic things to contend with.
LikeLike
I’d like to test a few things in a follow-up post.
I can’t introduce or maintain the correct amount of numerals and metadata into another test. But what I could try is remove all such things from Voynichese and see what that does to entropy.
The results won’t prove anything, but if I chuck out everything that’s non-alphabetic, we should be left with improved entropy values.
So what should I remove? You say:
* Neal keys
* line-terminal -am
* EVA -y
* EVA -dy for good measure?
I’ll also test your other suggestions, like what difference it makes to include a- with -iin clusters.
But if I want to remove possible numerals, what would be my best shot?
LikeLike
Just checking… when you introduce ‘C’ and ‘S’ (etc.etc.), also your h1 increases. I assume you took that into account.
LikeLike
Yes, as soon as I start introducing new characters, I use h2/h1. At step 4 and 5 I was hardly able to increase this value, which I blame in part on rising h1. I’m going to write a follow-up post calculating the impact of each change individually as well.
LikeLike
Enjoyable post, Koen. My time is too limited right now to post on the entropy and TTY discussions, but I look forward to each one.
Just one thought…
Since we don’t yet know what the VMS is, don’t be afraid to try a few things that might blow the numbers through the roof (at least once in a while). Staying within comfortable limits for natural language is only applicable if, in some way, the VMS is natural language.
LikeLiked by 1 person
In the end it looks like this “problem” of low entropy is only a matter of the way the Voynichese sounds are transliterated into Voynichese script. Especially the first (two) letters have few information. As if starting every noun (or verb) with the same letter? Voynich word entropy is similar to e.g. Latin, actually in between Dante’s and Pliny’s.
The very interesting analysis by René Zanfbergen can be found here:
http://www.voynich.nu/extra/wordent.html
It also hows the effect of using another transliteration (Cuva)
http://www.voynich.nu/extra/sp_analysis.html#cuva
LikeLike
Ger – interesting you should say that. I recall Philip Neal saying – oh years ago – that Voynichese seems to ‘behave like Latin’.
LikeLike
As long as your base unit is “words”, my experience is that Voynichese sits at the low end of Latin, high end of European vernacular.
As soon as you look within words though, it’s way below anything else, though closer to Germanic than to Latin.
So when somebody says “Voynichese is like….”, it really matters what they are talking about. I’m going to keep working on the effects of transcription on statistics for some posts, so I’m hoping to understand more about this.
LikeLike
Actually I said: ” Voynich word entropy is similar to e.g.(!) Latin” because that happened to be the language he compared it to in that place. Actually I was led to the above article by his quote “Furthermore, I have addressed the question how it is possible that the character and digraph entropy of the Voynich MS text is so much lower than that of, say, Latin, while the word entropy (…) is similar.”
Here:
http://www.voynich.nu/a2_char.html
Latin being only one of a large group of lannguages that behave similarly.
LikeLike
“Similar to e.g. Latin” is the same as “like Latin”. Nobody is saying the relationship is exclusive 🙂
And on top of that, the situation is much more complex. As I’ve shown in the TTR posts, Voynichese switches categories when you consider smaller windows. And its words may even if large-window vocabulary density is like Latin, many of those words in Voynichese are very similar to one another.
That is why I’m looking at character entropy now. But doing so without questioning your transcription method is useless. I think Nick has some very good ideas about this, which I’ll discuss in the next post.
LikeLike
Koen said: “, many of those words in Voynichese are very similar to one another.”
Again, that might be a matter of how the Voynichese spoken sounds were transliterated. Just for example(!) if (certain) vowels were left out that would in any language lead to many similar (shorter) words. Why would we say it became illegible if the scribes thought it was not? We haven’t got a clue as to what Voynichese is anyway…
LikeLike
Koen, it was my reaction to “I recall Philip Neal saying – oh years ago – that Voynichese seems to ‘behave like Latin’.” which certainly suggested Latin and not German, nor French, nor Dutch, nor English,… 🙂
LikeLike
Ger/Koen,
I was rather hoping someone better informed than I might (at last) help me understand what Neal might have meant by “behaves like”.. the phrase always intrigued me.
LikeLike
Koen – a question related to Nick’s comment about numerals. What do you think might happen to a language’s entropy if – for example – material like that in the first part of the Zibaldone da Canal had simply written the numbers ‘instead of ‘using numerals.
I can’t be bothered hauling out my copy and quoting an actual example, but they often run, ” in Venice silk is sold four rotuli six soldi but Tunis six soldi a Genoese rotula and ten soldi the rotula of Egypt”… and so on.
If the question’s foolish, or impossible of answer, don’t hesitate to say so.
I chose the example because that mss was in Venice in 1422, and is another sold to the Beinecke by H.P. Kraus. Others would do as well.
Zibaldone da Canal (Beinecke MS 327)
catalogue entry https://pre1600ms.beinecke.library.yale.edu/docs/pre1600.ms327.htm
LikeLike
That’s an interesting question, but impossible to say without testing it. And for that I’d need a copy-pastable text of some size.
What would certainly happen is that h1 goes up, and probably h2 as well. There are various formulas we can use, but as I understand it, both h1 and h2 have to be taken into account.
Introducing more characters (like numerals) that are used with some frequency will raise h1. If those characters also decrease predictability, it will increase h2. In that case, h2/h1 might remain similar, though again it’s hard to tell beforehand.
My prediction is that numerals are relatively chaotic, and they would increase h2, while we need it to get lower. Or, transcribe Voynichese in a way that makes it higher
Our problem is that Voynichese is way too predictable. You are not too much into text analysis yourself, but still if I mention a glyph, you know where it goes. Gallows in front, benches in front, [a] in the middle, [y] front or end, [iin] at the end and so forth.This is the problem we must address first, and numerals won’t help much with that.
Nick’s other point about punctuation or “metadata” might be more relevant, but even harder to test.
LikeLike
A language like Japanese that uses only a very limited number of vowels V (a,e,i,o,u) and consonants C (_,k,s,t,n,h,m,y,r,w) and is mainly structured as CVCVCV.. must have a low h1 and h2. After all one is able to say as much as in any language so the words are shaped taking allmost all possible combinations of CVCV… Even more so when, as in Voynich, words appear to be short. Problem to check this with Japanese is the large number of Chinese, Dutch and English words that behave completely different. So what if somebody found a (likely very old) Japanese text not containing these intruders?
Oh, by the way… I am NOT saying the VM is in Japanese 🙂
.
LikeLike
Japanese words are rather long although there is a high frequency of very short words. However for H1 and H2 the length is not an issue.
LikeLike
To “achieve” low entropy one can also refrain from modifying syllables with the “-sign. They are used to extend the number of consonants but the text would remain readable. It’s a bit like writing German without umlaut, but then for vowels.
LikeLike
Ger, with Japanese I expect you’d have to run separate tests for male and female speech, as for higher and lower class speech. The honorifics employed in aristocratic Japanese and the different endings for nouns and verbs and so on.. Apart from anything else the difference between ‘o’ compounds.
LikeLike
Yes, that might show differences. However as for entropy the “physical” structure of limited C’s and V’s as CVCV… remains the same. Most important (and difficult) would be to exclude texts with words originating from other languages.
LikeLiked by 1 person
So I assume you are thinking in terms of Romanized Japanese (Romanji)? I suspect that its entropy won’t be that tremendously low as Voynichese. For example, what follows “a” in Japanese? What follows “o”? Yes, your options are more limited than in Latin, but there is still much more freedom than in Voynichese.
Loan words are not a problem, since they are all squeezed into the tight phonetic structure of Japanese. So this is not something to worry about nor is, I think, the gender or politeness of the text. H2 is really about the amount of options you have for the following letter.
It’s still an interesting question, and I wonder whether Romanji would be lower than German and by how much. When I get home later today I’ll look for a suitable text.
LikeLike
I haven’t read what Neal wrote about it, but VMS text does behave like Latin in the sense that certain glyphs are placed in certain positions in tokens.
The glyphs EVA-y, EVA-m, EVA-g, and possibly EVA-dy (if one relates it to the Latin “-bus” abbreviation) are all shaped and positioned as one would expect to find them in texts that are based on the Latin character set.
LikeLike
Okay so I tested Japanese in Romaji (where you get the CVCV alterations). Its h2/h1 is 0.715, which is about the same as the lowest medieval text in my corpus. VM sits around 0.55, depending on the section and transcription.
This is more or less what I was expecting. Japanese transcribed alphabetically does have some entropy-lowering properties, but still it is not predictable enough to rival Voynichese.
What I tried next, is split the Romaji text into “syllables” by adding a space after every vowel. This is a direct hit to h2, because suddenly it’s very predictable what will follow after a vowel (namely a space). This artificial procedure lowers h2/h1 to 0.649, which is still not low enough.
This should give you an idea how bad the situation is with Voynichese’s character entropy. So that’s why I’m still focusing on how to tweak an EVA transcription to get the most out of it.
LikeLike
I’ve been tinkering with it a bit more, and if I really “sillabify” Romaji in the most consistent way possible, I can get its h2/h1 down to 0.566, which is Voynich level. This requires using an alphabet to convert a non-alphabetic writing system and splitting the resulting words into pseudo-syllables though. It looks like this: ga ki mi wo ma mo ru ka ra a na ta no….
LikeLike
Yes I think here the spaces force the entropy down. And it surely does not look like Voynichese… But certainly Japanese people might be able to read the full contents, which makes that a representation on Voynich level of a full blown modern language.
LikeLike
Koen,
I now see you’ve been busy too… But this is what I came up with.
To see what happens with Japanese I tried to find Japanese romanized text on the internet. After an hour searching I only found a site with short articles which I combined to get 10233 letters worth. My program produced a conditional second order entropy of 2.75 – well below my tests on modern Dutch and English (3.22 and 3.27) and in the end not far away from your 2.41 for Herbal-A with substitutions. Since I might have made programming errors I will give the other values so you can compare.
Herbal-A stage 0 2.07
Herbal-A stage 1 2.24
Herbal-A stage 2 2.25
Herbal-A stage 3 2.35
Herbal-A stage 6 2.41
If the numbers agree I intend to report this more detailed on my site.
In the mean time I would be happy to be shown romanized Japanese on the internet…
Ger Hungerink.
LikeLike
The Japanese texts are the (longer) romanized stories from:
https://www.thoughtco.com/search?q=romaji&offset=0
[three pages with links]
Modern Japanese with the usual word formation.
LikeLike
Ger, I used similar methods to cobble together enough Romaji text. This is fine for testing character entropy.
Note that I know nothing about programming, and until recently I had the greatest difficulties understanding this whole entropy business. I usually have a strong dislike for anything that smells like mathematics 🙂 But I really wanted to test different ways of parsing Voynichese, and this is the best way to do it. So I did my best to catch up and I’m kind of learning these things while doing these experiments.
The code I use is nablator’s, see here: https://www.voynich.ninja/thread-2770-post-30610.html#pid30610
I’m certain it’s a good code, so maybe you can try it and compare it to your results.
LikeLike
Thanks Koen,
As to the foreign words in Japanese: Dutch and English in general are transliterated with CV syllables it seems. However the Chinese readings of characters were adopted in Japanese a long time ago and – I think – in developing their hiragana they reckoned with that. The Chinese readings often do not follow the CVCVCV… pattern. Frequently one sees two consonants as defined above like ky, by, ry, … and two vowels like ou, ei, uu, … However even though Chinese readings are very frequent it might well have no effect on entropy at all. But would there be any substantial Japanese text without them?
LikeLike
“If more progress is to be made, it might be necessary to detect other situations like [a] and [y], where two glyphs might be positional variations of the same “phoneme”. If you have any suggestions, I’ll gladly test them.”
My suggestion would be to restore “deleted” [y]. It’s a theory I’ve had for a while now and is related to the equivalence of [y] and [a].
In its simplest form: where [e] is not followed by [e], [y], [o], or [a], insert [y] (or [a], depending on how you’re treating [y/a]).
I’m not sure exactly the difference it will make to entropy. It make even make it worse, but at least I can make an argument for this change so it would be interesting to see.
LikeLike
I did a quick test with four files:
– Original
– [y] inserted
– [y] to [a]
– [y] inserted, then [y] to [a]
The effect of inserting [y] in both cases (whether [y] and [a] remain separate or not) is small. It decreases h1 and h2 in a similar amount, and slightly lowers h2/h1.
– Inserting missing [y] in the unmodified file lowers h2 by 0.01.
– Compared to the file where [y] and [a] are equated, the addition of missing [y] lowers h2 by 0.04. (quite a bit).
By contrast, simply equating [y] and [a] *raises* h2 by 0.03.
LikeLiked by 1 person
Thanks for doing that Koen. I suppose it doesn’t surprise me that it makes things worse.
LikeLike